GDPR: three practical focus points and how Azure helps

Since 25 May 2018 already more than four years the General Data Protection Regulation GDPR has been fully in effect throughout Europe. Which elements created the biggest challenges for software driven organisations?
The first major fine of no less than fifty million euros was imposed by the French data protection authority CNIL. The world’s largest search engine Google was said to have been insufficiently transparent toward its end users. This made us wonder how the law has been implemented by organisations closer to home and where they still see challenges. In particular we looked at how this has unfolded within software driven organisations. These are organisations in which software development and self built systems play a central role in their success.
Using exploratory research conducted at eight organisations we outline the three biggest challenges.
Which elements cause the most concerns
Data security data minimisation data filtering anonymisation privacy by design they are just a few aspects of the GDPR that can be crucial. Some remain constantly top of mind while others may not receive the attention they deserve. Looking back which aspects create the biggest challenges?
Through a questionnaire and expert interview we examined the following GDPR elements at eight organisations:
- Data minimisation. How does a company ensure that it monitors the data it stores and only keeps data for which it has consent?
- Logging. Which changes does the company track? And how does it log metadata such as proof of user consent?
- Anonymisation. What is done to anonymise data as much as possible?
- Pseudonymisation. Does the company apply pseudonymisation to the appropriate data?
- Data security. How does the company guarantee that the data it holds is stored securely?
- Insight. Does the company know what data it has?
- Test data. Is there a clear distinction between production data and data used for testing?
- Data filtering. Where does filtering actually take place?
- Rights. How is authorisation arranged within the company and how is it enforced?
- Third parties. What agreements does the company have with third parties regarding data exchange?
- Privacy by default. Are the settings of an application or system as private as possible by default?
- Privacy by design. Are systems that are being built or expanded truly designed and built with privacy in mind?
- Rights of the end user. Does an end user really have access to the GDPR rights such as the right to deletion the right to correction the right to restriction of processing and the right to access?
- Accountability. How does the company demonstrate accountability to end users and authorities?
Based on the questionnaires and expert interviews a clear top three emerged. A top three of topics that receive the least attention and where software driven organisations experience the greatest challenges:
-
Pseudonymisation and anonymisation
-
Data minimisation
-
Test data
Below we explain each aspect.
Pseudonymisation and anonymisation
Pseudonymisation ensures that personal data cannot be traced back to a person without additional information. It means that the storage of personal data must involve encryption or other pseudonymisation tools.
With current technology encryption is often easy to implement. Many types of databases can encrypt the entire storage. But there are also databases that allow you to go a step further and encrypt automatically per table column or row. A good example is the Azure SQL database which has the feature Always Encrypted. This technique ensures that all data or specific parts of it in the database are encrypted even during transport from the database to an application and decrypted only when it arrives at the application.
Anonymisation ensures that data can no longer be traced back to a person. Unlike pseudonymisation anonymised personal data cannot be decrypted. In application development and data analysis it is crucial to apply anonymisation as early as possible.
A growing amount of data is highly valuable to companies for example for analysis forecasts or testing. Many analyses can be performed without knowing the identity of the person. The value of the data remains the same while the individual’s privacy is protected.
Note that the Dutch Data Protection Authority explicitly states that hashing the creation of a unique code that cannot be reversed to the original value is not considered sufficient to meet this requirement.
After anonymising a dataset the question remains is the data anonymous enough? To answer this you can use k-anonymity. This is a model that determines how easily a specific user can be identified within a dataset based on a combination of attributes.
Data minimisation
One way to ensure privacy is data minimisation storing only the data necessary for the system’s purpose.
In the ideal scenario only strictly necessary data is saved when it enters the system. If that is not possible the data should be removed as soon as it becomes unnecessary. A clear example is a checkout page of an online store. If a product needs to be delivered to you your name address and phone number are required and your email address is needed for confirmation and invoicing. However these forms often collect more information than needed. Information intended to enrich the customer profile or serve other goals unrelated to the order. Removing optional fields would make such a form compliant with data minimisation principles.
Data minimisation is easiest to apply when implementing a new system. During the design phase you must ensure that only the necessary information is stored and that redundant data is deleted when possible. It is also important to separate data based on system goals. Data collected for a specific purpose at the beginning of a process should ideally be removed immediately after.
Test data
Test data may not contain production data except in cases where it can be proven that no alternatives are sufficient.
When processing personal data an organisation must clearly define the purpose of the processing and its legal basis. This should be tied to primary business processes such as an insurer offering policies and handling claims efficiently.
Primary processes are supported by IT processes which we build every day for our clients. If personal data is also involved in these IT processes they become subject to the same processing rules and must be evaluated for legal basis and purpose. Often this aligns directly with the primary process but sometimes the purpose is less clear.
Consider our earlier example. May software for an online store be tested using real customer information so that orders can be processed faster in the future? It is important to assess whether all alternatives are insufficient. Alternatives include pseudonymisation or the use of synthetic data. If production data is still chosen development teams must prove that test data is insufficient.
Our Azure tip
We have only explained the three biggest focus points based on research at eight software driven organisations. The other aspects also lead to challenging discussions and difficult decisions. What challenge does your organisation face?
We want to highlight a Microsoft Azure tool we have had good experiences with which may help you gain more insight into the data you collect. This is the Data Discovery and Classification tool in Azure designed for SQL Database.
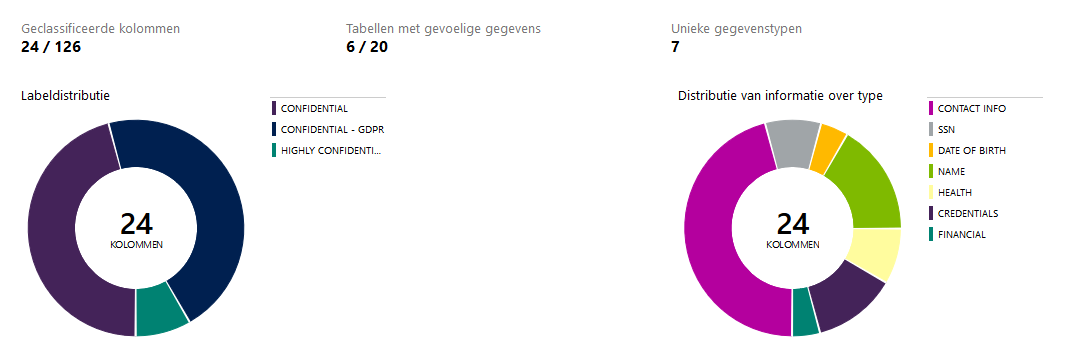
For the earlier mentioned focus points the challenge often begins with the questions “what data do we actually have?” and “what does this data mean?”. Take again a health insurer and the dataset it uses. Its employees know they have your personal data and receive claims but do they know exactly which fields a claim contains and what consequences these fields can have when combined with another table?
To gain insight you can use the Data Discovery and Classification tool in Azure designed for SQL Database. Azure allows you to view the data model of a database and assign a classification to each field or column such as Confidential or Confidential GDPR. Based on field names and model names Azure provides suggestions to guide your classification process. With these classifications you can take measures for example in logging or in selecting which fields to keep.
Software driven organisations
The introduction of the General Data Protection Regulation was quite some time ago. But data security privacy by design data minimisation anonymisation and all related principles are more important than ever. This is especially true for organisations where software development and self built systems play a central role in their success.
Be aware of the challenges your organisation faces. Privacy and security are essential matters not secondary ones.
More blog posts
-
Securing web applications and the OWASP Top 10
To properly secure software, you must understand how hackers operate. Ethical hacking helps identify vulnerabilities in systems, processes, and human behavior.Content typeBlog
-
Secure Your Software by Thinking Like a Hacker
To properly secure software, you must understand how hackers operate. Ethical hacking helps identify vulnerabilities in systems, processes, and human behavior.Content typeBlog
-
Exploring the essentials of professional software engineering
Jelle explored what defines a professional software engineer and shared insights from personal experience. Below is a brief recap of the topics he discussed.
Content typeBlog
Stay up to date with our tech updates!
Sign up and receive a biweekly update with the latest knowledge and developments.