JSON data opslaan in SQL databases
In deze blog legt Christian uit hoe je JSON-data kunt opslaan en verwerken binnen SQL Server en Azure SQL Database. Daarbij laat hij zien hoe je flexibel kunt werken met schemaless data dankzij de ingebouwde JSON-functionaliteiten van SQL Server.

JavaScript Object Notation, oftewel JSON, is een veelgebruikt formaat voor data-uitwisseling. Zoals de naam al doet vermoeden, is JSON oorspronkelijk de manier waarop objecten in JavaScript worden genoteerd. Tegenwoordig is het echter uitgegroeid tot een standaard voor data-uitwisseling tussen systemen, ongeacht welke programmeertaal gebruikt wordt.
JSON is een tekstueel formaat en daardoor “human readable” en zelfomschrijvend. In dat opzicht is het vergelijkbaar met XML, dat jarenlang de standaard was voor data-uitwisseling. Omdat JSON compacter is en in veel situaties eenvoudiger in gebruik, bijvoorbeeld binnen JavaScript-applicaties, is de populariteit van JSON sterk toegenomen en heeft het XML in veel scenario’s vervangen.
De stap van data-uitwisseling naar data-opslag is vervolgens klein. JSON is immers in feite gewoon tekst. Databases kunnen dergelijke teksten zonder problemen opslaan, maar zodra je binnen die data wilt zoeken of gegevens wilt aanpassen, ontstaan er uitdagingen.
SQL Server en Azure SQL Database bieden daarom functionaliteit om effectief met JSON-data te werken. Met een relatief klein aantal functies ontstaat een breed scala aan mogelijkheden voor het uitlezen, aanpassen en verwerken van JSON binnen een relationele database.
Schemaless
SQL Server-databases hebben een duidelijk schema. Van een tabel ligt vast hoeveel kolommen deze bevat, wat de namen van die kolommen zijn en welk type data erin opgeslagen mag worden, zoals tekst, getallen of datums.
JSON-data is daarin veel flexibeler. Je kunt bijvoorbeeld een lijst met objecten hebben waarbij ieder object andere eigenschappen bevat.
{"employees":[
{ "firstName":"John", "lastName":"Doe", "Manager":"Peter Jones"},
{ "firstName":"Anna", "lastName":"Vries", "Middlename":"de", "Age":"40"},
{ "firstName":"Peter", "lastName":"Jones" , "Offices": ["Eindhoven", "Amsterdam"] }
]}In dit voorbeeld bevat iedere werknemer andere eigenschappen. Binnen JSON is dat volledig valide, maar in een SQL-database levert dit uitdagingen op. Relationele databases zijn immers gebaseerd op een vast schema.
Juist daarom kan het interessant zijn om JSON-data rechtstreeks in de database op te slaan, in plaats van deze eerst om te zetten naar een traditionele tabellenstructuur met vaste kolommen.
JSON in SQL databases
Hieronder zie je een overzicht van de JSON-ondersteuning in SQL Server en Azure SQL Database. De meeste interessante functionaliteit bevindt zich in het blauwe vlak: de built-in functions. Voordat we daar dieper op ingaan, kijken we eerst naar FOR JSON en OPENJSON.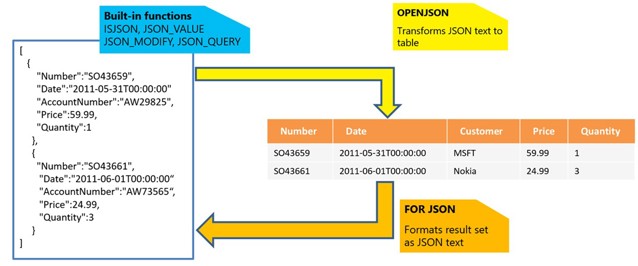
FOR JSON
Door FOR JSON toe te voegen aan een query wordt het resultaat niet meer als tabel weergegeven, maar als JSON-array. Bekijk onderstaande query en let daarbij vooral op de onderste regel.

De toevoeging PATH, in combinatie met de twee kolomaliassen, zorgt ervoor dat Category als child-object onderdeel wordt van het productobject.

OPENJONS
OPENJSON is eigenlijk het tegenovergestelde van FOR JSON. Waar FOR JSON een tabelstructuur omzet naar JSON, zorgt OPENJSON er juist voor dat JSON als tabelstructuur kan worden weergegeven.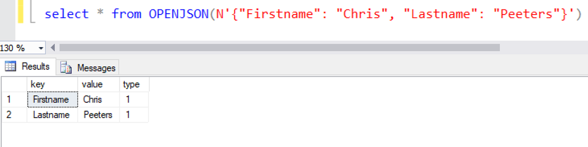
Door een WITH-statement toe te voegen, kun je nauwkeurig bepalen welke gegevens uit de JSON gebruikt moeten worden. In dit voorbeeld wordt een variabele gebruikt, maar dit kan uiteraard ook data uit een databasekolom zijn.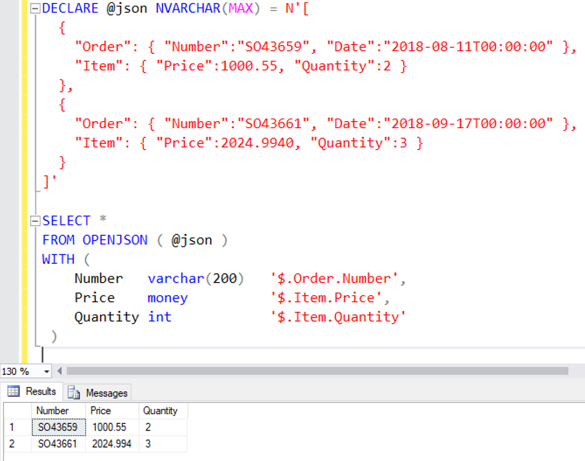
Build-in functions
SQL Server biedt vier built-in JSON-functies. Hiermee kun je effectief met JSON-data werken, terwijl de gegevens gewoon als platte tekst in een NVARCHAR-kolom worden opgeslagen.
De functies worden hieronder uitgelegd aan de hand van een Users-tabel met één kolom: User. In deze kolom staan JSON-objecten met informatie over gebruikers.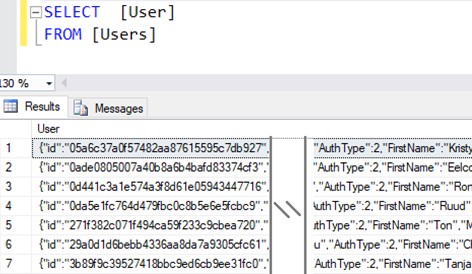
De ISJSON()-functie kan bijvoorbeeld gebruikt worden als CHECK-constraint op een tabel. De gebruikersobjecten mogen verschillende eigenschappen bevatten, maar de inhoud moet wel valide JSON zijn. Hiervoor kan een constraint worden toegevoegd zoals hieronder weergegeven.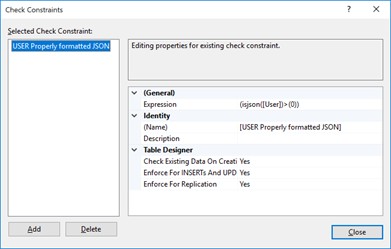
Met JSON_VALUE() kun je een specifieke waarde uitlezen, bijvoorbeeld de eigenschap JobDescription van een gebruiker. Sommige objecten bevatten een lege waarde en sommige objecten bevatten de property helemaal niet, maar de query levert in alle gevallen een duidelijk resultaat op.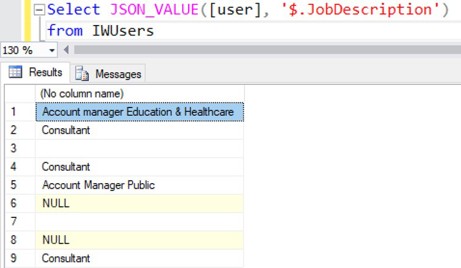
De JSON_QUERY()-functie lijkt sterk op JSON_VALUE(), omdat beide gebruikt worden om gegevens uit JSON op te vragen. Het verschil is dat JSON_VALUE() één enkele waarde retourneert, terwijl JSON_QUERY() een object of array teruggeeft. Dit kan bijvoorbeeld gebruikt worden om het Address child-object van een gebruiker op te vragen.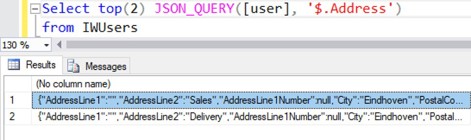
De JSON-functies kunnen niet alleen in de SELECT-lijst gebruikt worden, maar ook in bijvoorbeeld een WHERE- of ORDER BY-clause.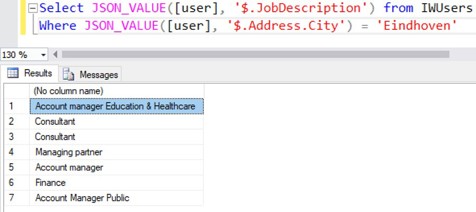
Indexeren
De snelheid waarmee deze queries worden uitgevoerd is behoorlijk hoog. In ieder geval sneller en minder foutgevoelig dan zelf met LIKE '%...%' proberen gegevens uit JSON te filteren. Toch zijn er scenario’s waarbij de performance van indexen noodzakelijk is.
Omdat JSON als tekst wordt opgeslagen, is het niet direct mogelijk om een index aan te maken op een specifieke eigenschap binnen een JSON-object. Dit is echter goed op te lossen met zogenaamde persisted computed columns.
Een computed column berekent zijn waarde op basis van een functie, bijvoorbeeld een JSON_VALUE()-functie. Door deze computed column ook als PERSISTED te definiëren, wordt de berekende waarde daadwerkelijk opgeslagen in de tabel. Hierdoor kan de kolom worden voorzien van indexen en zelfs gebruikt worden voor primary- en foreign keys.
In onderstaand voorbeeld zie je naast de User-kolom twee persisted computed columns: Id en Email.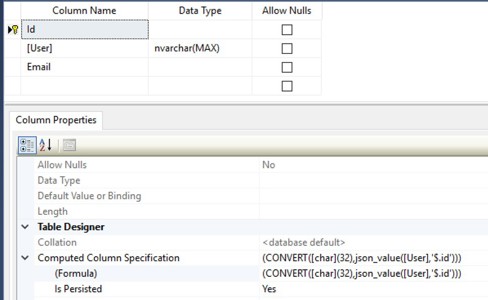
Wanneer een JSON-object in de User-kolom wordt geplaatst of aangepast, worden de waarden van Id en Email automatisch bijgewerkt. Door indexen op deze kolommen te plaatsen, kunnen zoekopdrachten en joins op eigenschappen uit het JSON-object supersnel worden uitgevoerd.
Usecases
Er zijn diverse scenario’s waarin het werken met JSON in een database interessant kan zijn:
- Een webapplicatie of service (Web API) werkt met JSON-objecten. In plaats van objecten telkens te parsen of te serialiseren, kun je ze rechtstreeks opslaan, ophalen en retourneren.
- De objecten hebben geen vast schema, of het schema verandert regelmatig. Daardoor is het lastig om de data op te slaan in traditionele SQL-tabellen.
- Er is eigenlijk behoefte aan een NoSQL-oplossing, maar je wilt toch SQL Server blijven gebruiken, bijvoorbeeld omdat de rest van de de data daar ook al is opgeslagen.
- Het normaliseren van data kan ertoe leiden dat joins erg complex en traag worden, doordat gegevens uit tientallen tabellen gecombineerd moeten worden om één entiteit op te bouwen.
- SQL Server biedt functionaliteit die in sommige NoSQL-databases ontbreekt.
- Je hebt veel kennis van T-SQL en wilt die kennis blijven gebruiken.
Zelf heb ik deze functionaliteit toegepast binnen een SaaS-oplossing. Het product werd aangeboden aan duizenden klanten, waarbij iedere klant een eigen database kreeg, onder andere vanwege security en onderhoud.
Bij grote aantallen databases worden schemawijzigingen al snel een uitdaging. Denk bijvoorbeeld aan het toevoegen van een extra kolom voor een nieuwe feature. Door gebruik te maken van JSON speelt dat probleem veel minder. Nieuwe objecten krijgen simpelweg een extra property, zonder dat de database zelf aangepast hoeft te worden.
Meer informatie over SaaS oplossingen, Azure of SQL Server?
Neem dan gerust contact met ons op of bespreek jouw specifieke situatie.
Meer blogposts
-
Krijg meer gedaan met C# pattern matching
Deze blog biedt een praktisch overzicht van C# pattern matching en laat zien hoe moderne patterns bijdragen aan compactere, beter leesbare en onderhoudbare code.
ContenttypeBlog
-
Regex in SQL Server 2025 & Azure SQL
SQL Server 2025 introduceert native regex-ondersteuning, waarmee patroonherkenning, validatie en datatransformatie eenvoudiger, leesbaarder en beter onderhoudbaar worden dan met traditionele stringfuncties.ContenttypeBlog
-
Blind SQL injection: wat het is en hoe je het voorkomt
Introductie tot SQL-injectie en Blind SQL-injectie: hoe aanvallers data uitlezen en manipuleren en hoe je dit voorkomt met veilige technieken zoals parameterized queries en inputvalidatie.
ContenttypeBlog
Altijd op de hoogte met onze tech-updates!
Schrijf je in en ontvang om de week een update met de nieuwste kennis en ontwikkelingen.